
How to operationalize Machine Learning with business policy and IT systems
For enterprise applications and business automation, Machine Learning (ML) is rarely used in isolation. The deployed ML model is almost always surrounded by a “policy layer” or set of business rules to govern how it’s invoked and how to interpret the results. For details on why these rules are needed see this previous article.
As a result, we’re left with three largely independent life-cycles, each producing new versions for different reasons:

New ML models are created when we have new data to train on, when data scientists refine their models or apply new algorithms. Meanwhile, business analysts refine the business policies, manage introduction of new offerings or marketing promotions. On the IT side, upgrades happen when new systems are introduced, new technology is applied or new application versions are developed.
As expected, since Data Science, Business and IT are separate departments and separately roles, our industry has arrived at largely independent solutions for governance:
- DATA SCIENCE: MLOps is focused at governance of ML models, include re-training, versioning and monitoring for drift and fairness.
- BUSINESS: Digital Decisioning, or Decision Management- or Automation Platforms occupy themselves with versioning of business rules, workflows or other forms of business policy.
- IT: CI/CD and Data Governance is focused on supporting applications development and governance of data, respectively.
In effect, we now have three semi-independent life-cycles that need to be coordinated. We can either allow them to spin autonomously, using “latest and greatest” from each, or we can lock them together, forcing a “global versioning” of sorts.
Which one you should choose depends on the context, which is what we’ll explore in this article. We’ll use three classic ML use cases to make this more concrete:
- Customer Churn — managing customer retention in retail or telco
- Product Recommendations — ranking offers based on propensity-to-buy
- Loan Risk Scoring — assessing risk of default for loan underwriting
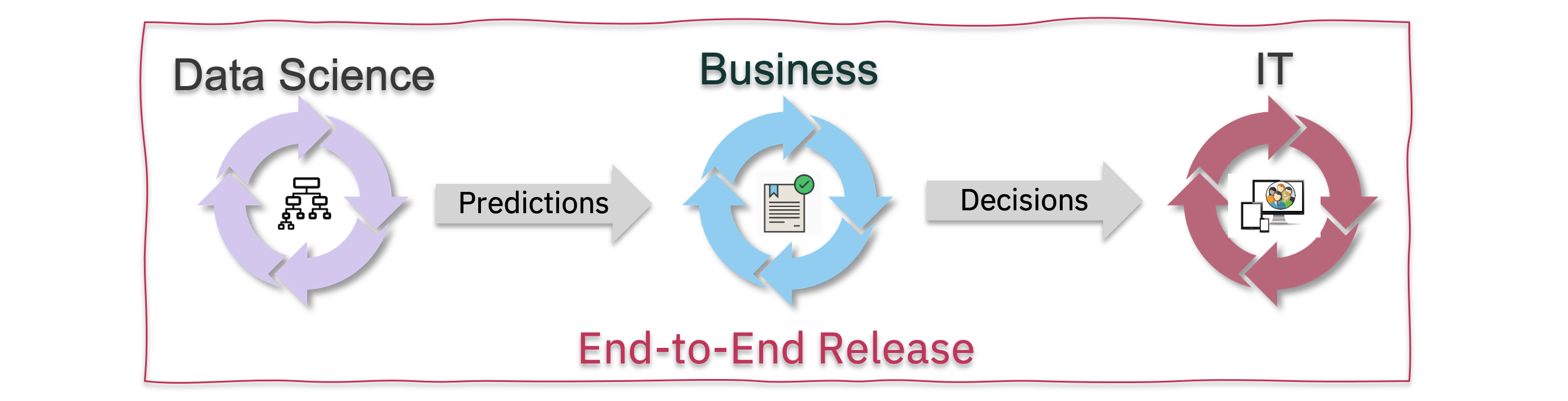
“All at once”: End-to-end Upgrades
As a first example, we’ll explore a case where we need to coordinate across:
Let’s say we have a prediction of churn risk — the probability that a customer will cancel their subscription for a product — and that this prediction is currently using an ML model trained on CustomerSegment, ProductsSubscribed, TimeAsClient and MonthlyUsage.
These four pieces of data captures the type of client, how many products they subscribe to, and how much they use them. However, to also capture how recently the customer made an active decision to continue their business with us, we could also include a new field, say, TimeOfLastSubscription.
Adding this new data fields triggers changes across the board:
- The ML training needs to find and pick up the new data field from some operational data store (provided by some IT system). When invoked, the re-trained ML model now requires the new TimeOfLastSubscription field in addition to the original four parameters.
- On the business side, we now need to provide the new field when asking for an ML-based prediction. In addition, since our predictions are now better, we might be able to remove existing policy rules (e.g. “if customer subscribed to a product less than 3 months ago, never offer retention offers”).
- The ripple effect continues into the IT systems, that now also need to provide TimeOfLastSubscription when asking for a retention offer decision. The IT system responsible for tracking subscriptions also needs to make this data available to the ML training, closing the loop.
In summary, when you’re adding data to the entire loop, you normally need make all changes in a coordinated fashion across Data Science, Business and IT. Think of this as a “major upgrade”.
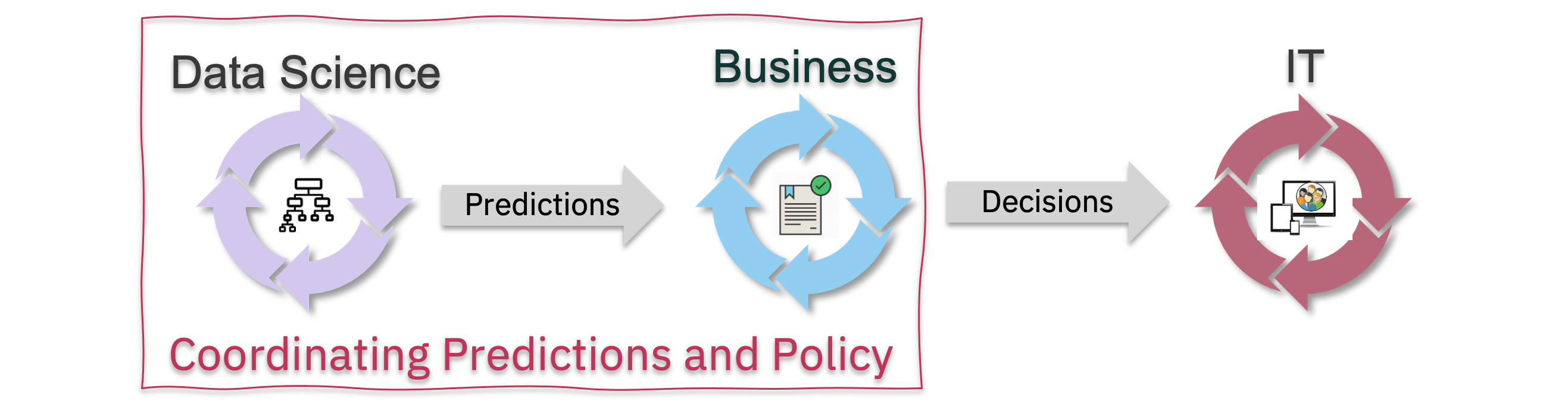
“ML + Rules”: Coordinated Upgrades of Prediction and Policy
As a second example, we’ll look at a case where ML and Policy versions need coordination, but not IT systems.
Consider a basic product recommendation system, where we use ML to deliver a “Propensity to buy” prediction. For a certain customer and product pair, this predicts the likely hood that the customer will purchase the product if offered. This prediction allows us to create a ranked list of product to promote to each customer. Surrounding that prediction we typically have a set of rules to filter our products the customer is not eligible for, that are not available in customer’s geography or that the customer already owns.
Now consider the introduction of a new product in our product catalog. Initially, we have very few customers who own the product, so the ML model is unlikely to recommend it accurately. Result is we don’t recommend it to enough customers, or to the wrong ones, and therefore adoption of the new product is slow.
This “chicken and the egg” problem needs to be resolved through active intervention, for example by overriding the ML-based predictions in order to recommend the new products and bootstrap the adoption. In this approach, we add a rule that “steals” a percentage of recommendations for older products that are similar in target audience to the new product, and redirects those recommendations towards the new product. Over time, as the ML model catches up and starts to recommend the new product sufficiently often, this redirection rule can be phased out.
From a practical governance perspective, this requires us to coordinate the upgrade to the new ML model with a new version of the business polices (which include the redirection rule).
This use case is an example of a general situation, where new or re-trained ML models need to be introduced gradually into operational systems. When predictions are not (yet) reliable —for whatever reason —there’s a period of time where we ignore or adjust predictions to achieve desired business outcomes.
“Use Latest” : Independent ML Upgrades
In many situations, the predictions from ML models evolve much slower than is the case with the previous two examples. In these periods of stability, between disruptions, we can re-train and upgrade the ML models frequently and automatically without need for coordination with policy rules or review of IT systems.
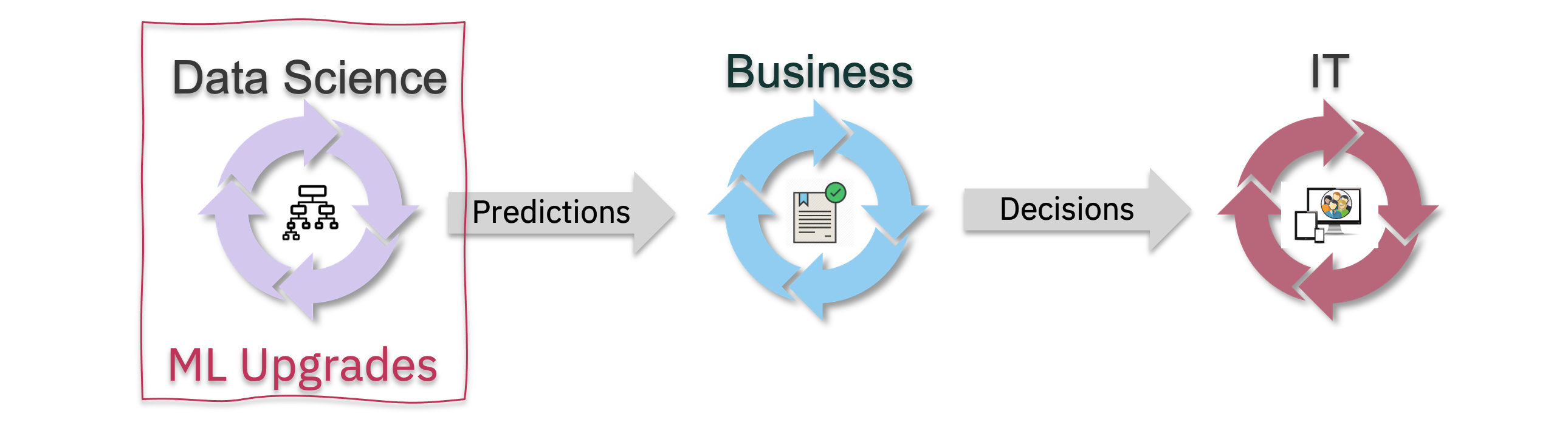
Consider for example a risk score in a loan approval scenario. An ML model is used to assess the risk of a customer defaulting on a loan, given the customer’s information and history, combined with the size and type of loan requested. This risk model can be retrained frequently to make scoring more precise, but the parameters required to invoke the model remains the same and the returned predictions will only change gradually over time.
In these cases, when a prediction is required we can always invoke the latest ML model version, and no adjustments to policy rules is required. However, this requires that the pipelines used for re-training the model is robust and able to detect data errors, e.g., and that the ML model is monitored for drift over time.
In addition, even with these safe-guards, a cautious business team would nonetheless monthly or quarterly perform a business simulation — across policy rules and predictions — to ensure that loan decisions generated provide expected business outcomes and complies with regulations around fairness, etc.
Summary
Applying Machine Learning to business automation isn’t necessarily difficult because of the sophisticated ML techniques required. It can often be based mostly on structured data, and “classic” ML approaches such as regression or decision trees are often sufficient for scoring, risk assessments and classification of business transactions.
What can be tricky is the “operational” aspect of business automation (decisions are made at scale) and ever-shifting business goals and policy rules. Improving ML-based predictions — while policies are changing —requires approaches that vary based on the use case and business context.
In this article we looked at three scenarios:
- End-to-end release across Data Science, Business and IT
- Coordination of just Data Science and Business versions
- Independent ML re-training
Greger works for IBM and is based in France. The above article is personal and does not necessarily represent IBM’s positions, strategies or opinions.

