
Today, most business value is derived from the analysis of data and products powered by data, rather than the software itself. The data generated by several application silos are combined and greatly enhanced to provide a better customer experience. Deriving value from the data includes building a unified data architecture and a collaborative effort of data engineering and data science teams. Data engineering involves building and maintaining the data infrastructure and data pipelines, and Data science involves transforming crude data into something useful and deriving insights through analytical and ML workloads.
Modern unified data architecture includes infrastructure, tools and technologies that create, manage and support data collection, processing, analytical and ML workloads. Building and operating the data architecture in an organization require deployments to cloud and colocations, use of several technologies (open source and proprietary) and languages (python, sql, java), and involves different skilled resources (engineers, scientists, analysts, admins). It is cost-effective to have a centralized data infrastructure to avoid duplication of data and efforts as well as to maintain a single source of truth in the organization for efficient usage.
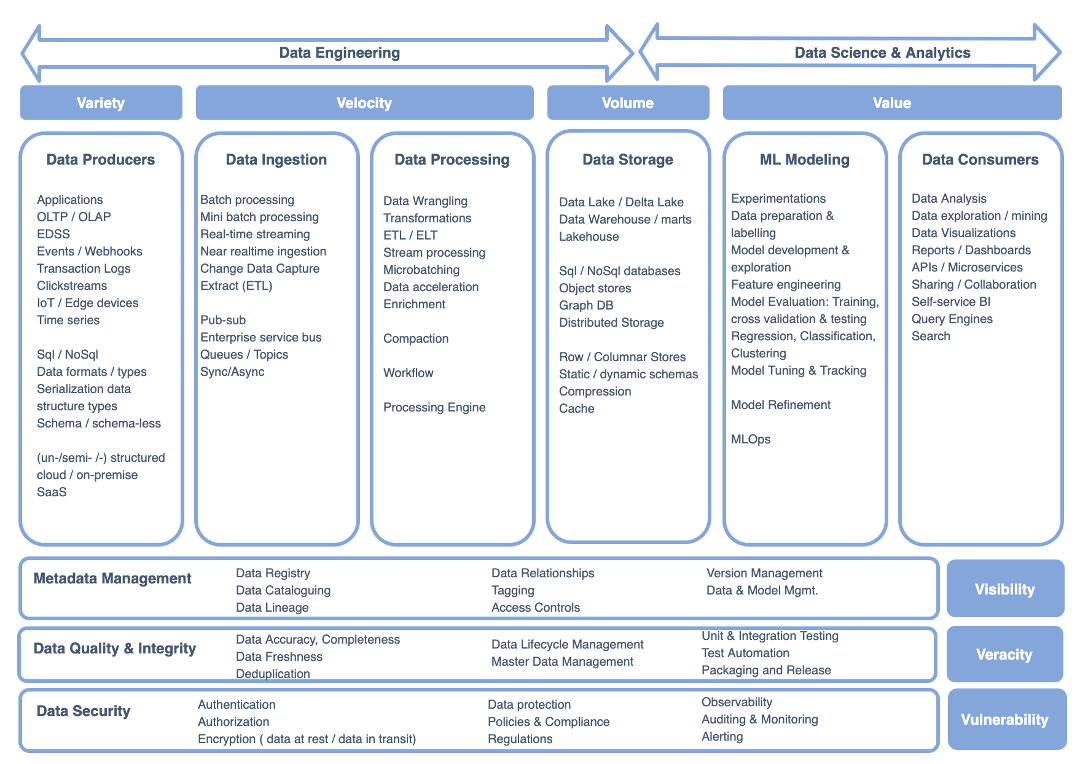
Many organizations generate, process and store massive amounts of data regularly for business analysis and operations. The challenges faced by big data analytical and processing applications are summarized as 3Vs, 5Vs, 7Vs or even more. In this article, I consider the 7 key challenges of modern data architectures:
- Variety: Data arrives in a variety of formats, structures, protocols and sizes from disparate data sources. The architecture should manage the data diversification while providing consistent data access. It should offer flexibility as well as enforce restrictions to schema variations.
- Velocity: The architecture should manage fast-moving data to generate outcomes in shorter timeframes as well as slow-moving data to generate outcomes on a periodic or on-demand basis. The solution should effectively scale-in or scale-out as the speed of data varies.
- Volume: The architecture should handle the amount of data coming in — small, big or bursts. It should effectively manage the incoming data as well as historical data and offer the right options for transactional and analytical use cases.
- Visibility: Data that exists in the system but not visible is as good (or bad) as that data doesn’t exist at all. The architecture should manage data visibility and accessibility along with its relationship and lineage details. It should enable data versioning to view how the datasets have mutated over time and roll-back to a specific version or time.
- Veracity: Veracity is the degree to which data is accurate, complete and trustworthy. Data should be cleansed, deduped, enriched and curated for data integrity so that businesses can trust the data and make a confident analysis.
- Vulnerability: Data should be protected from unauthorized access wherever it resides and restricted based on compliance policy changes. The data is observed over its flow and lifecycle to track how it is used and by whom.
- Value: The final outcome of the data architecture is to enable data-driven analysis for business decision-making or to build data-powered products to enhance the customer experience.
As shown in Figure 1., these challenges are surfaced at different stages as the data flows through the modern big data architectures. To address these challenges, the separation of data ingestion, processing, storage, ML modeling and consumers into separate isolated components makes it possible to independently repair, scale or replace resources in these stages without impacting others.
Data Producers
Data producers generate data in a variety of ways in structured, unstructured or semi-structured format. Data producers can be transactional applications and operational systems that generate relational data, or they can be social media mobile apps, IoT devices, clickstreams or log files that generate non-relational data. The data sources can have different data mutation rates — data that comes from OLTP transaction applications experience heavy write operations and data that arrive from other OLAP systems can experience heavy read but low write operations. Data produced from relational databases typically have static schemas whereas distributed non-relational data stores have dynamic schemas. Data produced by dissimilar systems arrive in different formats such as json, csv, parquet, avro etc.
Data Ingestion
The huge volume of data generated by the providers is ingested into big data system through various techniques such as batch ingestion, micro-batches, change data capture, publish-subscribe, sync-async, and stream ingestion. Both push and pull mechanism of data extraction is employed along with features such as ordering, message delivery guarantees, delivery confirmation, message retention, message aging and watermarking. The data architecture should effectively handle the performance, throughput, failure rate requirements and avoid throttling in the system. Data ingestion through massive batch processing is used for complex processing and deep analysis; real-time streaming is used for quick feedback and anomaly detections. Typically, batch ingestions at scheduled intervals have predictable workloads and on-the-fly batch ingestions have unpredictable workloads. For stream ingestions, the data should be query-able as soon as it enters the system and provides immediate actionable insights.
Data Processing
Data processing involves various methods such as cleansing, profiling, validating, enriching, and aggregating datasets. It involves data modeling and mapping source-destination schemas. The data architecture should support both schema enforcement to avoid inadvertent changes (schema-on-write) and at the same time offer flexibility to modify schemas (schema-on-read) as the requirements evolve. For slow-moving datasets, batch processing techniques are employed to churn large datasets, perform complex transformations and generate deep insights. Previously, batch processing used to be long-running jobs, but lower latencies are possible by the use of distributed massive parallel processing engines such as Spark. For fast-moving datasets, real-time streaming techniques such as aggregating and filtering on rolling time-windows are employed to generate immediate insights by the use of Spark streaming or Flink. Languages such as python, java, scala and sql are predominantly used for data processing.
Previously, Lambda/Kappa architectures provide unified analytics but separate paths for batch and real-time processing resulting in duplicate resources and effort. However, with modern architectures through the use of frameworks such as databricks, it is possible to combine batch and real-time processing into a single path. As the count and complexity of data processing jobs increases, complex DAGs (Directed Acyclic Graphs) and efficient pipelines can be built using workflow tools such as Airflow, Nifi, Luigi, etc. along with virtualization container services such as Docker or Kubernetes. As data velocity changes, processing jobs should scale elastically to handle data bursts and data accelerations due to a sudden spike in usage or demand.
Data Storage
The data architecture should effectively manage the massive amounts of data processed and stored in the system through distributed storage, object stores and purpose-built storage options (nosql db, columnar db, timeseries db etc. ). Previously multi-cluster distributed Hadoop systems have combined storage and compute at each node. However, modern solutions decouple storage from compute so the same data can be analyzed with variety of compute engines. Decoupled storage employs efficient columnar data indexing and compression techniques. Centralized storage avoids duplication of data copies distributed across multiple systems and provides better access control to users. Cloud data lakes are essential components in any modern data solutions and store unlimited amounts of data. The fundamental challenge with data lakes are they are typically append-only and updating records is hard. Delta lakes and HUDI solutions solve this challenge by bringing ACID properties to data lakes. The performance of data processing is improved through properly configuring settings such as partition, vacuuming, compaction, shuffling, etc.
ML Modeling
After the datasets are prepared by the pipelines built by the data engineers, the data scientists will perform further curation, validation and labeling the data for feature engineering and model building. Scaling out data preparation is not the same as scaling out ML models. Scaling out ML is hard and training models are typically not multithreaded. Once the ML models are trained then the models are deployed at scale on multiple nodes, and the inference endpoints are generated to provide predictions.
The MLOps and DevOps will help the data engineers and data scientists to manage and automate the end-to-end ML workflows. The modern data architecture supports MLOps practices to enable automation and traceability of model training, testing, hyper-parameter updates and experiments so that ML models are deployed in production at scale. For tracking experiments and deploying ML models, open-source tools such as MLflow or Kubeflow are used. Deploying a model to the production is not the end. The models are continuously monitored for any drifts in data and model accuracy. When any decline in model quality is detected, then the data received by the model are captured and compared with the training datasets. The models are retrained, redeployed to production and inference endpoints are updated again, and this process continues for the ML lifecycle. The effectiveness of model deployments to production are improved using shadow deployments, canary deployments and A/B testing.
Data Consumers
At the end of the data and ML pipelines, the value of the data and data architecture is derived by the data consumers, harnessing data through analytical services, data science, and operational products.
After all the processing, crunching and mining of data is performed, the goal is to provide actionable insights of value through interactive exploratory analysis, reports, visualization, data science and statistical modeling, so business can make evidence-based data-driven decisions. Depending upon the analytical maturity of the use cases, descriptive, predictive and prescriptive analysis are performed. Rich support for languages, query engines and libraries are available for analysis. Typical languages used for analysis are sql, python and R. Big data query engines such as hive, spark sql, cassandra cql, impala etc and Search engines such as Solr, Lucene, Elastic Search etc., are used. Data scientists use libraries such as pandas, matplotlib, numpy, scipy, scikitlearn, tensorflow, pytorch etc.
Data powered applications support live operations of the business through APIs and microservices from the data platform. The data products can use the APIs that are built upon the data stores to provide enriched information or they can be referential ML endpoints that provide predictions and recommendations.
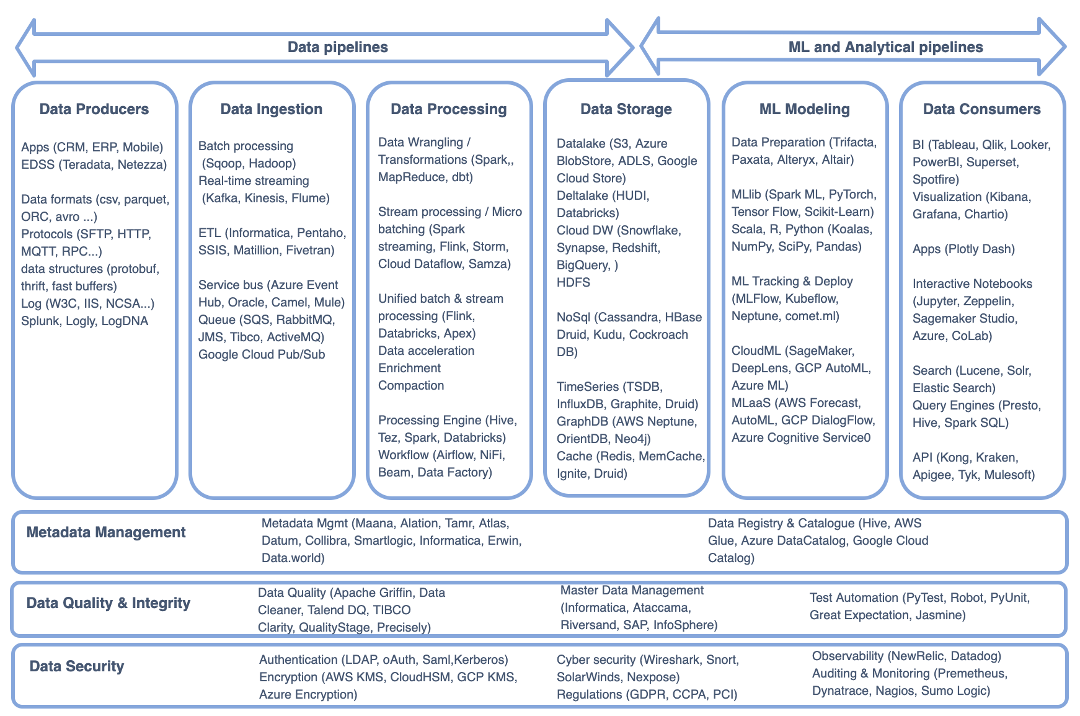
Figure 2 shows the various open-source and proprietary products available at each stage in building modern data architecture.
Metadata Management
Metadata management includes data cataloging, data relationship and data lineage techniques. Data cataloging offers smarter data scanning methods to automatically deduce data structures and mappings. It describes the data traits such as quality, lineage and profile statistics of a dataset. The data architecture should allow users to append tagging and keywords to easily search data assets. Data architecture can provide enhanced features such as automatically exposing correlations, data corruptions, joins, relationships and predictions within the data. As the variety and number of datasets increases, the metadata of big data applications can itself become so large that the data architecture should include search tools for data discovery and serve as data inventory. Scalable metadata management is required for democratized data access and self-service management.
Data Quality & Integrity
Data Quality is to ensure an accurate, complete and consistent record of data is maintained over its entire flow through different pipeline stages as well as its lifecycle. This ensures that the data is reliable and trustworthy for planning, decision making and operations. To ensure integrity of the data, we need to have full traceability and lineage information when the data enters the system and through all stages till the data reaches the consumer end points. Several basic techniques can be employed to validate the data integrity between source and destination datasets at each processing step such as comparing rowCounts, nullCounts, uniqueCounts, and md5 checkSums. Data corruptions can be detected and corrected by ensuring that referential integrity, entity relations and constraints of datasets are defined and met. Data integrity is maintained by providing selective update access only for authorized users and services, establishing data governance policies and employing data stewards.
Data Security
The data architecture should provide stringent security, compliance, privacy and protection mechanisms for data in all the different layers. Only authenticated and authorized users or services can access the data. PII information should be masked and hashed out. Modern data architectures provide automatic anonymization when patterns such as email, ssn, and credit card are detected. Data encryption methods are applied for data at rest and for data in transit. Observability and site reliability engineering methods are employed for auditing and alert mechanisms.
Modern data solutions utilize CI/CD and DevOps to manage and automate deployments and changes to the system by including build systems like Jenkins, configuration management systems like Puppet or Chef, and containers such as Dockers or Kubernetes.
The major cloud providers (AWS, Azure and Google) offer end-to-end solutions to build unified integrated data architecture. In Figure 3, each of the stages is mapped to the services offered by the major cloud providers.

The big data unified architecture has a plethora of tools and technologies available today and this is an area where rapid changes are happening. Each of these tools and technologies has certain strengths that make them the right choice for a particular scenario, however, they could be a terrible selection for a different use case. Hence for tool selection, understanding your organization’s use case and requirements are important, to begin with. Then follows the evaluation and experimentation of tools with clear and time-bound goals, before picking the right tool. In this space, open-source technologies and services offered by major cloud providers (AWS, Azure, GCP) are generally preferred rather than being locked to proprietary vendor solutions. This space it continuously evolving, so identifying the right technologies, and being flexible to change and iterate are important to meet your business needs and build a competitive advantage.
References:
Source: https://towardsdatascience.com/modern-unified-data-architecture-38182304afcc

